Copyright 2012-2021 今日看点 All rights reserved. 苏ICP备13052634号-10
声明: 本站部分内容来源网络,如果你是该内容的作者,并且不希望本站发布你的内容,请与我们联系

我们将在24小时内删除
友情链接: 网站地图
转载自【菜J学Python】:用Python实现《沉默的真相》3万+弹幕情感分析
大家好,我是J哥。
以前我写过不少文本数据分析,比如《八佰》影评分析、《三十而已》热评分析等,但基本停留在可视化分析层面。本文将运用文本挖掘技术,对最近热播剧《沉默的真相》弹幕数据进行深入分析,希望对大家有一定的启发。
本文数据分析思路及步骤如下图所示,阅读本文需要10min,您可在「菜J学Python」公众号后台回复文本挖掘获取弹幕数据进行测试。
《沉默的真相》共12集,分集爬取,共生成12个csv格式的弹幕数据文件,保存在danmu文件夹中。通过glob方法遍历所有文件,读取数据并追加保存到danmu_all文件中。
csv_list = glob.glob('/菜J学Python/danmu/*.csv') print('共发现%s个CSV文件'% len(csv_list)) print('正在处理............') for i in csv_list: fr = open(i,'r').read() with open('danmu_all.csv','a') as f: f.write(fr) print('合并完毕!')清洗后数据如下所示:
机械压缩去重即数据句内的去重,我们发现弹幕内容存在例如"啊啊啊啊啊"这种数据,而实际做情感分析时,只需要一个“啊”即可。

情感分析是对带有感情色彩的主观性文本进行分析、处理、归纳和推理的过程。按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析。其中,前者多用于舆情监控和信息预测,后者可帮助用户了解某一产品在大众心目中的口碑。目前常见的情感极性分析方法主要是两种:基于情感词典的方法和基于机器学习的方法。
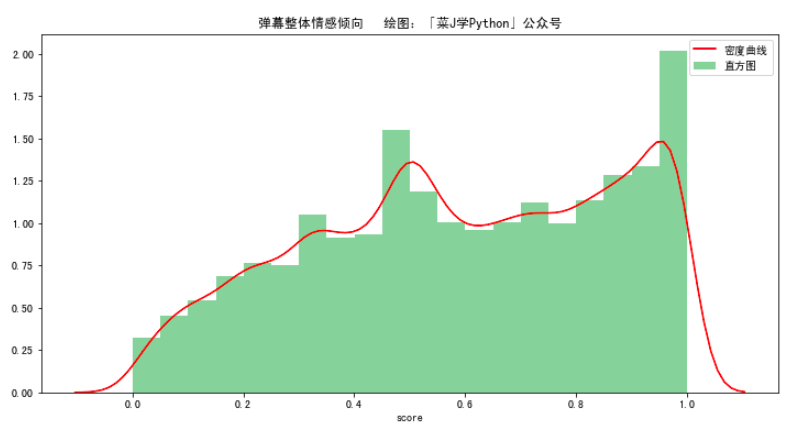
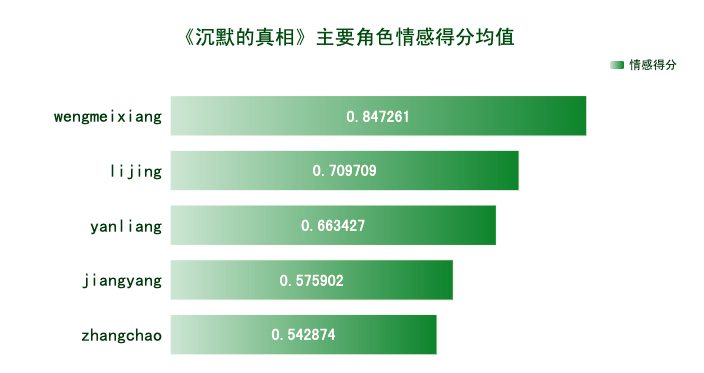
本文主要运用Python的第三方库SnowNLP对弹幕内容进行情感分析,使用方法很简单,计算出的情感score表示语义积极的概率,越接近0情感表现越消极,越接近1情感表现越积极。
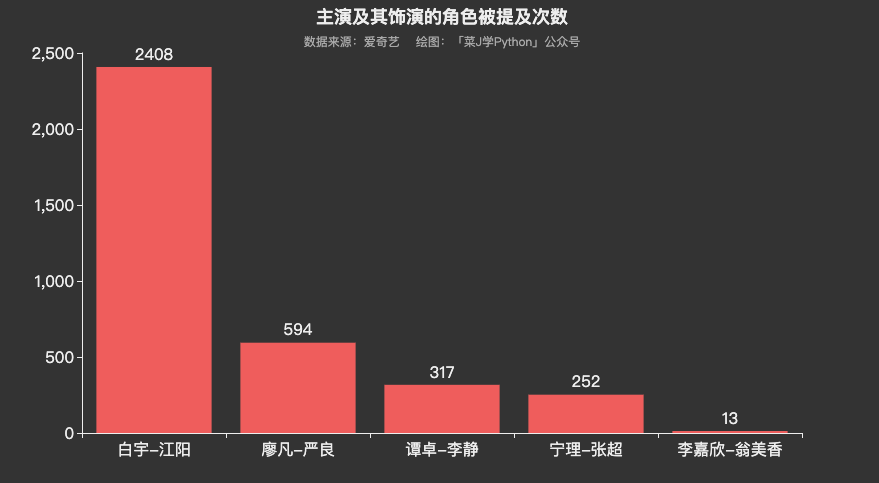
由各主要角色情感得分均值可知,观众对他们都表现出积极的情感。翁美香和李静的情感得分均值相对高一些,难道是男性观众偏多?江阳的情感倾向相对较低,可能是观众对作为正义化身的他惨遭各种不公而鸣不平吧。
首先,筛选出两大类分别进行分词。
本文来源:https://www.kandian5.com/articles/30362.html

在明朝近三百年的历史长河中,于谦以"粉骨碎身浑不怕,要留清白在人间"的铮铮铁骨,成为后世传颂的民族脊梁。这位历经永乐、宣德、正统、景泰四朝的股肱之臣,其人生轨迹既折射出传统士大夫的精神高度,也暴露出封...

在中国两千余年的帝制历史中,康熙帝(爱新觉罗·玄烨)以61年的在位时间成为“中国历史上在位时间最长的皇帝”。他的一生不仅见证了清朝的崛起与巩固,更在后宫中留下了四位皇后的传奇。这四位皇后各自承载着不同...

电影《即兴谋杀》正式开启预售,并发布“诡影随行”版终极预告和“暗处有诡”版终极海报。终极预告中上演着豪门惊悚猎杀,蛇蝎后妈设下致命陷阱,豪门独女谋划反击...

10月17日,由央视网出品的首档“她”视角人文访谈影像集《桃之夭夭》,在陈妍希“向左转、向右转”的破茧与抉择中落幕。一朵桃花盛开或许悄无声息,但一片桃林...

Rosé于23日在首尔国立剧场海雾林剧场举行的第16届“大韩民国大众文化艺术奖”上,获颁总统表彰,以表彰其在推动大众文化进步与韩流传播方面的卓越成就。她于去年1...

4月1日愚人节,是西方民间的传统节日。这天,人们以多种方式和周围的人开玩笑,但最晚只能开到中午12点,这是约定俗成的规矩。那么愚人节玩笑尺度开得太大,需要负责任吗?如果玩笑触犯了法律,给他人造成伤害,...

中国天眼的使用权限向全球开放,这只巨大的探索宇宙之眼,将更好地发挥效能,促进重大成果产出,为全人类探索和认识宇宙作出贡献。中国天眼究竟有多大呢? 中国天眼是最大的球面射电望远镜,2016年7月,中国完...

若是要说中国历史上主动提出离婚的女人,能与文绣其名的那肯定就要属李清照了。文绣之所以一下子出名了,那是因为她队溥仪皇帝提出了离婚,还差点让天津地方法院做出了离婚判决。而李清照之所以出名,是因为她不惜自...

这两天被堵了,网上传得沸沸扬扬,我看不少人都有点奇怪,苏伊士运河那么重要,为啥不挖宽点?挖宽点不就堵不了了嘛。作为一个严肃的作者,也为了让文章再过几个月还能看,干脆,我把苏伊士运河的前世今生都说一遍,...

中国天眼自使用以来,取得了不少观测成就。 2017年10月,发现2颗新脉冲星,距离地球分别约4100光年和1.6万光年,是中国射电望远镜首次发现脉冲星。2017年12月,FAST新发现3颗脉冲星,且这...

Copyright 2012-2021 今日看点 All rights reserved. 苏ICP备13052634号-10
声明: 本站部分内容来源网络,如果你是该内容的作者,并且不希望本站发布你的内容,请与我们联系
我们将在24小时内删除
友情链接: 网站地图