Copyright 2012-2021 今日看点 All rights reserved. 苏ICP备13052634号-10
声明: 本站部分内容来源网络,如果你是该内容的作者,并且不希望本站发布你的内容,请与我们联系

我们将在24小时内删除
友情链接: 网站地图

作者:J哥
源自:菜J学Python
本文将运用文本挖掘技术,对最近热播剧《沉默的真相》弹幕数据进行深入分析,希望对大家有一定的启发。
本文数据分析思路及步骤如下图所示,阅读本文需要10min,您可在「快学Python」公众号后台回复文本挖掘获取弹幕数据进行测试。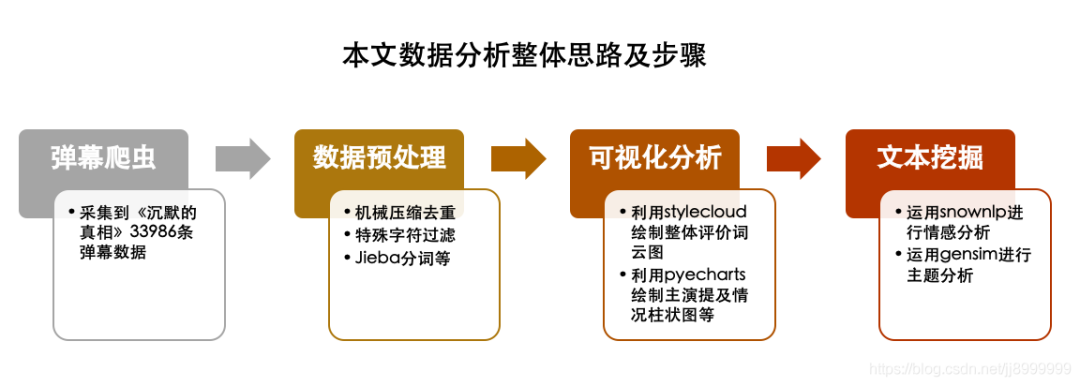
本文仅提供核心代码:
from xml.dom.minidom import parse《沉默的真相》共12集,分集爬取,共生成12个csv格式的弹幕数据文件,保存在danmu文件夹中。通过glob方法遍历所有文件,读取数据并追加保存到danmu_all文件中。
csv_list = glob.glob('/菜J学Python/danmu/*.csv')
机械压缩去重即数据句内的去重,我们发现弹幕内容存在例如"啊啊啊啊啊"这种数据,而实际做情感分析时,只需要一个“啊”即可。
应用以上函数,对弹幕内容进行句内去重。
df["danmu"] = df["danmu"].apply(yasuo)另外,我们还发现有些弹幕内容包含表情包、特殊符号等,这些脏数据也会对情感分析产生一定影响。

特殊字符直接通过正则表达式过滤,匹配出中文内容即可。
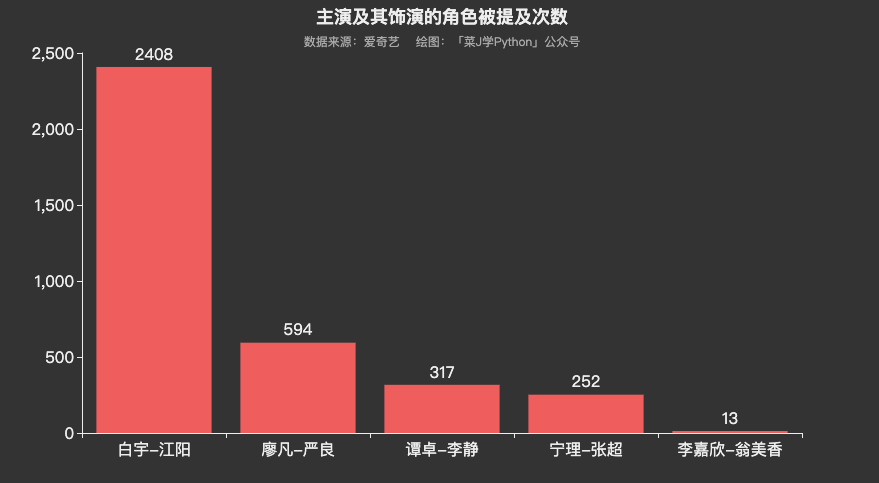
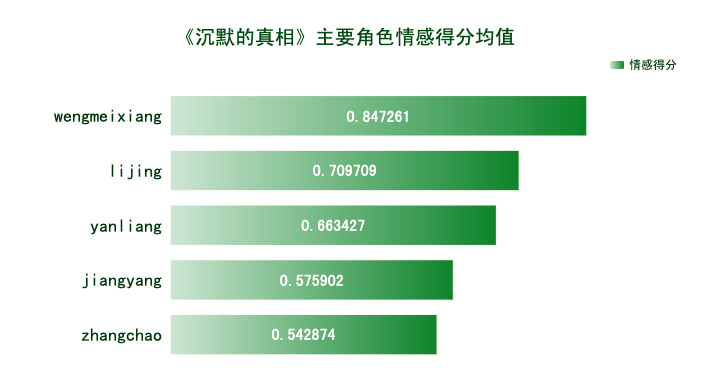
数据可视化分析部分代码本公众号往期原创文章已多次提及,本文不做赘述。从可视化图表来看,网友对《沉默的真相》还是相当认可的,尤其对白宇塑造的正义形象江阳,提及频率远高于其他角色。

情感分析是对带有感情色彩的主观性文本进行分析、处理、归纳和推理的过程。按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析。其中,前者多用于舆情监控和信息预测,后者可帮助用户了解某一产品在大众心目中的口碑。目前常见的情感极性分析方法主要是两种:基于情感词典的方法和基于机器学习的方法。
本文主要运用Python的第三方库SnowNLP对弹幕内容进行情感分析,使用方法很简单,计算出的情感score表示语义积极的概率,越接近0情感表现越消极,越接近1情感表现越积极。
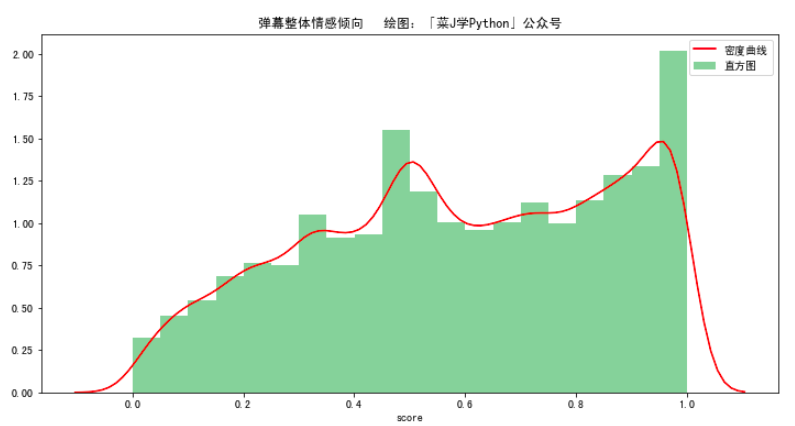
这里的主题分析主要是将弹幕情感得分划分为两类,分别为积极类(得分在0.8以上)和消极类(得分在0.3以下),然后再在各类里分别细分出5个主题,有助于挖掘出观众情感产生的原因。
首先,筛选出两大类分别进行分词。
#分词本文来源:https://www.kandian5.com/articles/30376.html

据台媒报道,10月29日,范姜彦丰发视频控诉棒棒堂王子邱胜翊介入自己家庭,和自己太太“粿粿”江玮琳发生婚外情。他表示:“我的信任和真心被狠狠践踏,最终成了戴绿帽的...
公元前205年彭城之战的溃败,将刘邦推向了历史争议的漩涡中心。当夏侯婴驾着马车在楚军追击中狂奔时,一个载入史册的场景发生了:刘邦三次将年幼的刘盈与鲁元公主踢下车,而车夫夏侯婴三次冒险救回。这场充满悖论...
三国时期,曹魏阵营中张郃与张辽同为"五子良将",但二人的军事风格与历史定位存在显著差异。通过对比战场指挥艺术、战略影响力及历史评价,可清晰看出张辽在战术创新与战场威慑力上更胜一筹,而张郃则以战略持久性...
公元221年,魏文帝曹丕赐死结发妻子甄宓,改立郭女王为后。这场看似简单的后宫更迭,实则是权力博弈、性格差异与时代局限共同编织的悲剧。当“洛神”的绝世风姿败给“女王”的权谋手腕,历史的暗流中,藏着三个致...
公元219年,关羽北伐襄樊的战鼓尚未停歇,荆州城防已悄然瓦解。这场改变三国格局的失利,既非单纯因关羽“大意”所致,也非单一因素促成,而是多重矛盾交织、内外势力博弈的必然结果。从战略决策到人性弱点,从盟...
公元217年,曹操在反复权衡十年后,最终将世子之位授予嫡长子曹丕。这场涉及二十余位儿子的继承人之争,不仅关乎曹魏政权的未来走向,更折射出东汉末年宗法制度、士族政治与个人能力的复杂博弈。曹操的选择,是传...
公元690年,67岁的武则天在洛阳则天门接受百官朝拜,改国号为周,成为中国历史上唯一的女皇帝。这个以女性身份建立的王朝,在十五年的跌宕起伏中,既创造了"贞观遗风"的盛世图景,也因权力博弈与制度困境走向...
中国历史上唯一的女皇帝武则天,以铁腕手段夺取李唐江山,却在晚年主动退位,最终以皇后身份与唐高宗合葬乾陵。这场权力交接的戏剧性转折,不仅源于武则天对身后事的精准布局,更折射出唐代政治生态中权力、血缘与利...
1542年冬,紫禁城西苑的丹炉火光摇曳,嘉靖皇帝朱厚熜正盯着道士炼制的“先天王粉丸”。这位沉迷丹药的帝王不会想到,二十四年后,他会因长期服用这类含汞朱砂的丹药,在剧烈抽搐中咽下最后一口气。当李时珍以太...

《如懿传》中,陆沐萍的戏份很少,她原本是太后安排在后宫的一枚棋子,当初皇上借玫嫔之手用绝育汤使其失去了生育的能力,在求依太后无果后,陆沐萍选择了依附于炩妃卫嬿婉,并事事对卫嬿婉进行阿谀奉承。没想到因争...

Copyright 2012-2021 今日看点 All rights reserved. 苏ICP备13052634号-10
声明: 本站部分内容来源网络,如果你是该内容的作者,并且不希望本站发布你的内容,请与我们联系
我们将在24小时内删除
友情链接: 网站地图